ソフトウェアエンジニアなら3秒で理解できる NFT 入門
はじめに
NFT って何ですか?
ブロックチェーン上に記録された一意なトークン識別子をその保有者のアドレスと紐付ける情報、およびそれを状態変数として保持するスマートコントラクトのこと。
以上。
え、それだけ?
はい。
「デジタル資産に唯一無二性を付与するインターネット以来の革命」なんじゃないの?
これを読んでください:
なるほど。ところで、この記事は何?
いま話題の NFT について、NFT の標準仕様である EIP-721 の仕様書と、それを実装しているスマートコントラクトのソースコードから読み解けることを解説する。一般向けの解説とは異なる視点から光を当てることで、ソフトウェアエンジニアに「あ、NFT って単にそういうことだったのか」と理解してもらえるようにすることを狙っている。
また、NFT がソフトウェアとして具体的にどう実装されているかを知ることは、今後、自分のやりたい事にブロックチェーン関連の要素技術をどう適用するか(あるいは適用できないか)を考える上で有用なはずである。
スマートコントラクトとは何か
「ブロックチェーンとは何か」「マイニングとは何か」については、記事の最初に紹介したスライドの最初の章で解説しているので、この分野に詳しくない人はまずそちらを参照してほしい。
スライドでは、スマートコントラクトを「ブロックチェーン上でプログラムを実行する仕組み」と簡単に説明したが、ソフトウェアエンジニア向けにもう少し具体的に書くと、「現在のブロックに記録された状態を読み取って、それを元に新しいブロックの状態を計算して書き出すプログラム」だと言える。*1
簡単な例として、整数を 1 ずつカウントするスマートコントラクトを考えてみよう。コントラクトはオブジェクト指向言語のクラスに対応するもので*2、その中に状態変数とそれを操作する関数を定義できる。ここでは Counter コントラクトに _count 変数を定義して、increment() 関数の呼び出しでカウントする:
contract Counter { uint256 private _count; function increment() public { _count += 1; } }
この increment() 関数がユーザから呼び出されると、以下のように動作する:
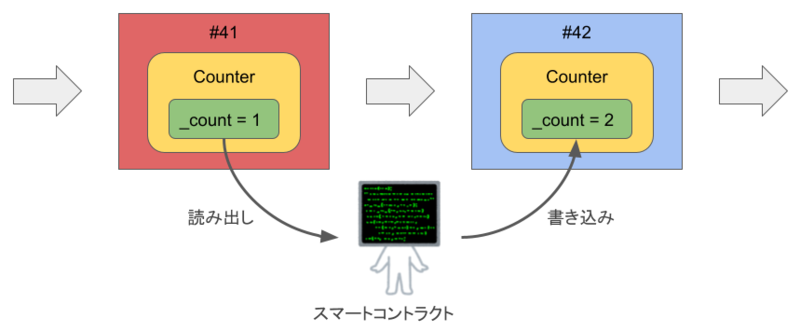
- 現在のブロック (#41) に記録された
_countの値(ここでは1)を読み出す - 読み出した値に
1を足す - 新しいブロック (#42) に計算結果 (
2) を書き込む
このように、コントラクトの状態変数はグローバルな(文字通り世界規模の)状態の一部としてブロックに記録され、関数を介して読み書きできる。つまり、スマートコントラクトとは「ブロックチェーンを記憶装置とする状態機械」のためのプログラムだと言える。また、コントラクトは自分自身の変数を操作するだけでなく、他のコントラクトの関数を呼ぶこともできる。
このコントラクトをブロックチェーン上で実行するには、それをコンパイルして得たバイトコードをブロックチェーンに登録(デプロイ)する。登録が完了すると、そのコントラクトに対してユーザアカウント (EOA; Externally Owned Account) と同様にアドレスが払い出されるので、ユーザや他のコントラクトは、対象のコントラクトアドレスにトランザクションを送ることで関数を実行できる。この際、その計算ステップ数に応じて、ユーザは「ガス代」と呼ばれる手数料を支払う必要がある。
なお、登録済みのコントラクトの修正や削除はできない。つまり、バグや脆弱性のあるコントラクトをデプロイしても後から修正できず、非常にリスクが高い。このため、本番のネットワークに登録するコントラクトは事前のテストや脆弱性診断が非常に重要とされている。*3
スマートコントラクトで独自の暗号通貨を発行する
ところで、スマートコントラクトを使うと独自の暗号通貨(トークン)を発行 (mint) できる。加えて Ethereum では、サードパーティ(取引所やウォレットなど)との互換性を保つために、独自トークンを扱うスマートコントラクトが従うべき仕様 (API) として EIP-20 を標準化している。
独自の暗号通貨の立ち上げ、と言うと敷居が高く聞こえるが、実は OpenZeppelin などの OSS プロジェクトが EIP-20 の実装を提供しており、これを使えば誰でもオレオレ暗号通貨が作れる。
また、その実装も特に難しいものではない。ポイントとなるのは以下の行だ:
contract ERC20 is Context, IERC20, IERC20Metadata { mapping(address => uint256) private _balances; ... }
つまり、ユーザごとの残高 (balance) が _balances 変数に書き込まれていて、対応するコントラクト関数(transfer(address _to, uint256 _value) など)の呼び出しで残高の移転が行われる。
独自貨幣の発行と流通という、一般に難易度の高い処理をここまで単純に記述できるのは、スマートコントラクトの独特な実行モデルによる。コントラクトは、マイニング競争でブロックの生成権を得たマイナーのコンピュータ上で一貫した順序付けの下に逐次実行されるので、そもそも並行性制御 (concurrency control) の問題が発生しないからだ。*4
スマートコントラクトで NFT を発行する
この EIP-20 を発展させたものが EIP-721、いわゆる NFT (Non-Fungible Token) だ。Fungible は「代替可能」という意味だが、それを否定している ("Non-") ので「代替不可能」となる。
世の中によくある NFT の記事では、この命名から説き起こして「代替不可能で唯一無二性のある〜」と繋げるものが多いが、そのような説明はわれわれソフトウェアエンジニアには分かりにくい。やはり、実際のソースコードを研究するのが理解への近道だろう。
というわけで、同様に OpenZeppelin が提供する EIP-721 の実装を見てみよう:
contract ERC721 is Context, ERC165, IERC721, IERC721Metadata { // Mapping from token ID to owner address mapping(uint256 => address) private _owners; function ownerOf(uint256 tokenId) public view virtual override returns (address) { address owner = _owners[tokenId]; require(owner != address(0), "ERC721: owner query for nonexistent token"); return owner; } ... }
見てのとおり、この任意のトークン ID を保有者のアドレスに紐付ける _owners 変数が NFT の核心部分であり、逆に言うとそれ以上のものではない。つまり、アドレスに残高が紐付けられているのが EIP-20 なら、その残高であるトークンを tokenId で個々に識別する機能を持つのが NFT だ。
NFT に関する一般向けの解説を読むと「何やら高尚で難しいもの」という印象を受けがちだが、その実装を検討すると実に単純なプログラムであると分かる。
NFT はどのように作品と紐付けられ(ていない)か
ところで、先ほどのコードには作品とトークンを紐付ける NFT メタデータを保持するコードが含まれていなかった。その部分は EIP-721 では optional な仕様として定義されている。同様に実装を見てみよう:
abstract contract ERC721URIStorage is ERC721 { // Optional mapping for token URIs mapping(uint256 => string) private _tokenURIs; function tokenURI(uint256 tokenId) public view virtual override returns (string memory) { ... } ... }
このように、実は NFT のメタデータはブロックチェーン上には記録されていない。代わりに、メタデータが置かれている外部の URI (tokenURI) を記録する。これは、コントラクトに書き込むデータ量が増えるほど「ガス代」が嵩むので、それを節約する目的がある。*5
この tokenURI は “ERC721 Metadata JSON Schema” に従う JSON を指してもよい (may) とされており、以下に示す name, description, image の三つのプロパティが定められている:
{ "title": "Asset Metadata", "type": "object", "properties": { "name": { "type": "string", "description": "Identifies the asset to which this NFT represents" }, "description": { "type": "string", "description": "Describes the asset to which this NFT represents" }, "image": { "type": "string", "description": "A URI pointing to a resource with mime type image/* representing the asset to which this NFT represents. Consider making any images at a width between 320 and 1080 pixels and aspect ratio between 1.91:1 and 4:5 inclusive." } } }
これを見ると、意外なことに、EIP-721 では NFT を紐付けたデジタル作品を特定するための機械可読な記述は標準化されていないことが分かる。image がそうなんじゃないの?と思うかもしれないが、該当項目の説明に「幅 320〜1080 ピクセルで 1.91:1 か 4:5 の画像」と書かれている通り、これは明らかにサムネイルの URI を記述するためのものだ。*6
では、実際に流通している NFT は、どのように自身と作品と紐付けているのだろうか。これは、NFT を実際に発行・流通しているマーケットプレイスに依存するというのが実情のようだ。例えば、NFT オークションサイトの最大手 OpenSea では、自サービスで解釈できる独自の NFT メタデータ仕様を定めている。
これを見ると、高解像度の画像を「NFT 化」するには、external_url に作品の本体をホストするサイトへの URI を書き込んでマーケットプレイスから誘導するしかない。以下の図は OpenSea のドキュメントより引用(赤丸は筆者):
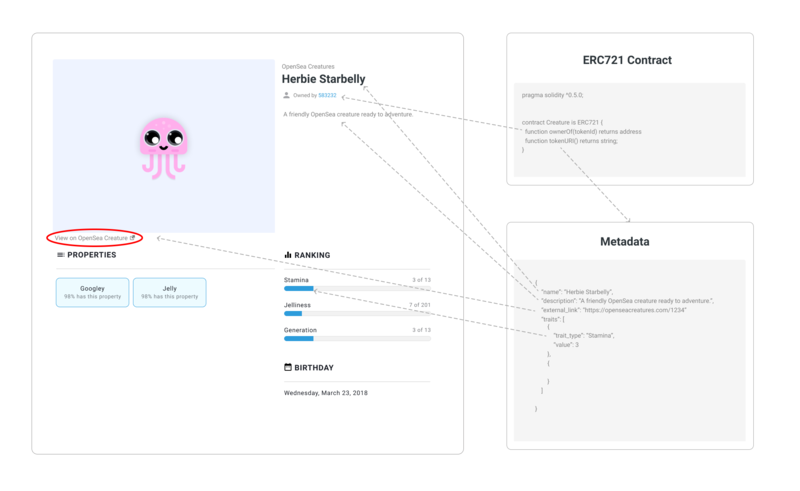
このように、標準仕様の NFT メタデータは作品データを特定するための情報を記述する方法が曖昧で、どちらかというと「マーケットプレイスが NFT のカタログページを作るための情報を提供する」という程度の位置付けに見える。例えば、紐付けた作品データの指紋(フィンガープリント)を記述する項目すら定義されていない。
これはつまり、購入した NFT 作品が別のものに改ざんされるリスクがあるということだ。例えば最近、暗号化メッセージアプリ Signal の創始者である @moxie 氏が、これが可能であると実証した経緯をブログ記事にまとめている。この記事では、OpenSea や Rarible などのマーケットプレイス上では普通のデジタルアートに見えるが、購入者が自分のウォレットからアクセスすると 💩 がデカデカと表示される NFT を作成して出品できたと報告している。*7
このように「デジタル資産に唯一無二性を付与する」と喧伝されている割には、価値の源泉であるはずの作品データ本体と NFT との機械的な紐付けがきちんと考慮されている様子がなく、なかなかに危うさを感じるのだが…。
NFT の本質は何か?
なぜ NFT のメタデータには作品データを特定する情報が含まれないのか。ここからは筆者の推測だが、その始まりにおいて NFT はゲームやデジタルトレーディングカードのための仕組みであり、作品データの管理は NFT のスコープではなかったからではないかと思う。
CryptoPunks の価値の源泉とは
一例として CryptoPunks を挙げる。これは 2017 年に始まった最も古い*8 NFT プロジェクトの一つで、多分に実験的な要素を含んでおり、後の EIP-721 の標準化に影響を与えた。
CryptoPunks はいわゆるジェネレーティブ・アート (Generative Art) で、アルゴリズムにより自動生成された 10,000 枚のドット絵のデジタルアイコンで構成され、その一枚一枚に通し番号 (#0〜#9999) が振られ NFT 化されている。また、ウェブ上でマーケットプレイスが提供されており、自分が保有するトークンを他のユーザと自由に取引できる。
開始当初はあまり注目を受けなかったようだが、2021 年に入った頃から突如としてセレブから多額の投資が集まり始め、3月にはそのうちの一枚である #7804 が 8 億円以上(!)という高額で取引されて話題となった。
そんな CryptoPunks の実体はもちろんスマートコントラクトであり、そのソースコードは以下の GitHub レポジトリから確認できる*9:
一方、NFT 化によって唯一無二性と高い資産価値を与えられた CryptoPunks のアイコンデータはどのように管理されているのだろうか。驚くべきことに、今や億円単位で取引されるそれらのアイコンデータはソースコードと共に GitHub にアップロードされている。punk の全アイコンが集約された punks.png という画像ファイルがそれだ。
{kind=link}
この画像ファイルのハッシュ値はコントラクトにハードコードされているため、これを使って入手した画像の真正性を検証することはできる。だが、画像自体はただのデジタルデータであり容易に複製できるため、希少性や唯一性を保証することはできない。
では、CryptoPunks の保有者は何に価値を見出して高値をつけているのだろうか? 少なくとも、画像データ自体の希少性ではないのは確かだろう。その謎に答えているのが、以下の TechCrunch の記事(原題: "The Cult of CryptoPunks")だ:
一言で言うと、punk 保有者たちのコミュニティが注目しているのはアイコンの属性だ。CryptoPunks のマーケットプレイスで閲覧できる各アイコンの詳細画面の Attributes(属性)という項目を見ると、その punk の特徴(男性か女性か、帽子を被っているか、…)と、同じ属性を持っている punk の数が書かれている。記事によれば、この属性がトークンの価値に大きく影響するようだ。
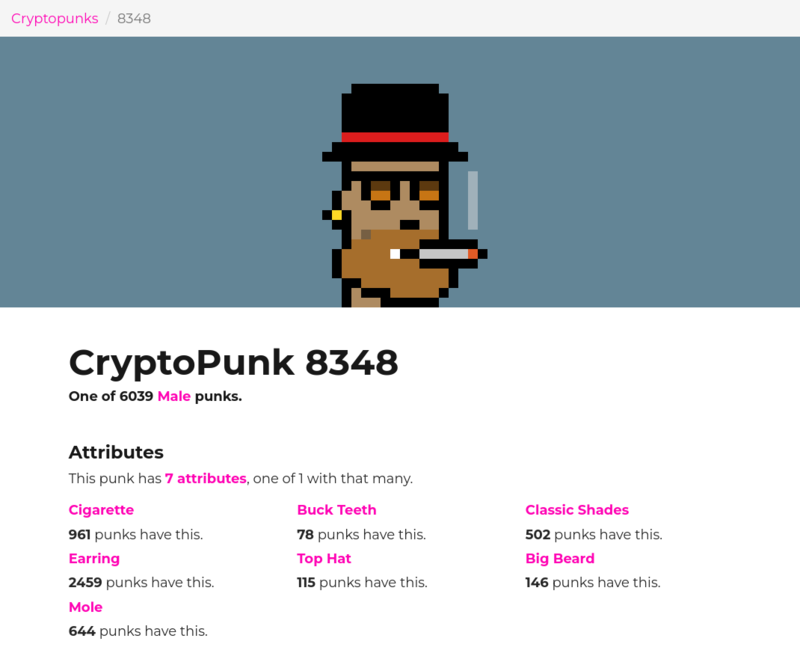
例えば、最初に紹介した 8 億円の punk は 10,000 体のうち 9 体しか存在しない宇宙人の punk である点が評価されたと言われており、画像データの希少性ではなく、発行者が割り当てた枠の希少性から価値が生まれるという構図が生まれている。他にも、punk の属性に基づく様々な価格決定メカニズムが働いている。記事によれば、例えば以下のような具合だ:
物事は常に予測できるとは限らない。パンクの属性として最も一般的な、イヤリングを付けたパンクは、最もレアな属性であるビーニー帽をかぶったパンクよりもはるかに低い価格で取引されている。しかし3Dメガネをかけた何百ものパンクは、数が少ない緑色のピエロの髪をしたパンクよりも高額のプレミアムを獲得する傾向にある。市場での勢いが不規則に増す属性もある。例えばここ数週間、パーカーを着たパンクの市場が特に過熱している。
...
30歳の暗号投資家であるマエガード氏はオーストラリアのブリスベンを拠点とし、クリプトパンクの価値に誰よりも投資している。彼は最近、特に珍しい「属性のない」女性のパンクを100万ドル(約1億1000万円)以上で販売した。彼は、最も希少なパンクの1つ(最も希少という人もいる)のオーナーでもある。このパンクは、7つのユニークな属性を持つことから「7-atty」という異名を取り、パンク伝説の聖地になっている。
イーサリアムの「最古のNFTプロジェクト」CryptoPunksをめぐる驚くべき熱狂 | TechCrunch Japan
この図式の成立に重要な役割を果たしているのがマーケットプレイスのウェブサービスだ。実は、CryptoPunks の NFT には属性を表すメタデータは記録されていない。しかし、マーケットプレイスがブロックチェーンから取得した情報に punk の属性情報を付加して掲示することでユーザがそのトークンの希少性を認識できるようになり、結果として売買の活性化に繋がっている。
このように、CryptoPunks のコレクションとしての価値の源泉は NFT でもアイコンの画像データでもなく、マーケットプレイスが提供するユーザ体験にその本質があると言えそうだ。
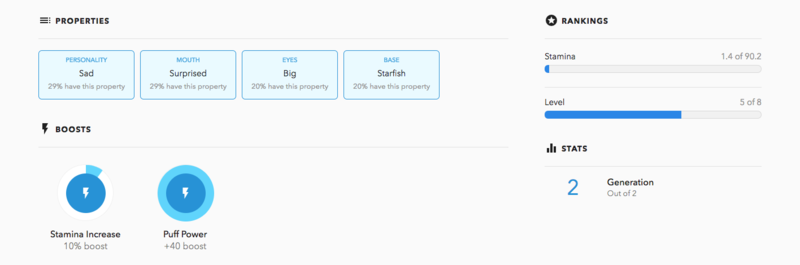
属性情報によってトークンの購買意欲を掻き立てる仕組みは、その後に立ち上げられた OpenSea にも引き継がれている。前述の、OpenSea が解釈できる独自メタデータの一つである attributes 属性がそれだ。OpenSea では attributes にトークンの属性を文字列や数字で指定すると、それが作品ページ内で以下のようにビジュアル表示される。これは、CryptoPunks がマーケットプレイス上で提供していた属性情報をメタデータに埋め込むことで、より汎用的に利用できるようにしたものと考えていいだろう。
最近、CryptoPunks を開発した Larva Labs はマーケットプレイスのアプリ自体を OSS 化し、Larva Labs 以外の人間が自由にホスティングできる「分散化」を推し進めている。この取り組みによって、たとえ今後、何らかの理由で公式のマーケットプレイスが閉鎖されてもユーザは将来に渡って punk の取引を続けることができるので、長期的な CryptoPunks の資産価値の安定性を高めることができる。*10
このことも、NFT の価値は単体では成立するものではなく、それを支えるパーツとしてマーケットプレイスが欠かせないことを示していると言えるだろう。
NFT はトレーディングカードである
CryptoPunks のこのようなあり方は、作品の美術的価値や文脈、そしてモノとしての希少性を評価するアートとはかなり性質が異なる。それは、どちらかといえば各カードに描かれたキャラクターの人気度や、その発行数量(コモンとかレアとか)によって価格が決まるトレーディングカードの文脈に近いと言える。*11
一般に、トレーディングカードやソシャゲで重要なのはコレクション性があることだ。そして、レアカードを買ったりガチャで SSR キャラを手に入れても、そこに描かれている絵柄やイラストの所有権を主張できるわけではないし、保有者もそこに価値を見出しているわけではない。つまり、この文脈において、トークンの保有者が作品の所有権や著作権を取得できるか、そのデータがどこに保存されているか、そもそもそれが唯一のコピーなのか、といったことは大して重要ではないということになる。
このことからも分かるように、CryptoPunks のような NFT は巷間で言われる「デジタルデータの資産化」ではなく、マーケットプレイスでの取引の集積の上に成り立つある種のゲームに見立てるべきであるように思う。何なら「人は何に資産的価値を見出すのか」ということを根底から問う、かなり興味深い社会実験であると評しても良い。例えば、かつて一斉を風靡した Cookie Clicker というゲームが、「人は何に達成感を感じるのか」を問うたように。
問題は、そこから生まれた NFT という仕組みが、アートという「モノを希少品として排他的に扱うことで価値を生み出す」ような文脈に持ち込まれたことではないか。
「顧客が本当に必要だったもの」を作る
最初に紹介したスライドでも述べたように NFT を「資産の所有権を表すもの」と見立てるのは法的な根拠がないだけでなく、技術的にも有効に保護する手立てがないため、無理があると言わざるを得ない。NFT ができるのは、あくまで「ユーザがトークン(≠資産)を排他的に保有していることを証明する」ことでしかないからだ。
「NFT」概念のブラックボックス化が孕む陥穽
この点を改良する試みがないではない。EIP-721 の規格化に関する issue では「NFT 化したファイルのハッシュ値の書き込みを必須にすべきだ」という問題提起がなされているし、メタデータの改ざんなどの問題に対処するために、EIP-721 の拡張として以下のような仕様が提案されている:
しかし、これらの提案に対するスマートコントラクト開発者たちからの関心は低く、標準化に向けた議論は停滞しているようだ。また、これらの課題を克服しても、「デジタルデータは複製可能である」という根本的な「欠陥」が解決するわけではない。
すでに見てきたように、NFT の技術的なアイデアは「ブロックチェーン上にトークン ID と保有者のアドレスを紐付けるデータベースを作る」という非常に単純なものだ。基本的なソフトウェア開発の知識があれば誰にでも実装できるが、故に、それ単体では機能として不十分なユースケースも多い。
しかし、そういうものに「NFT」というクリプティックなラベルが貼られてそのままバズワード化したことで、その内実がブラックボックスになってしまった。そして、ソフトウェアの専門家ではない人たちに対して、あたかも「デジタルデータを資産化する夢の技術」として喧伝され、それが様々な問題を引き起こしているのが現状だろう。*12
「NFT」を超えてゆけ
個人的には、ブロックチェーンの「特定の国家や企業に依存せずに、全世界から利用可能な記録を残せる」という性質を活用できる応用(アプリケーション)は何かしら有りうるだろうと思っている。また、ブロックチェーン以外の(中央集権的な)要素技術を使って実現できるアプリケーションでも、この領域のビジネスに資金が投下されてエコシステムが整備されつつあることを考えれば、それを当て込んだ技術選定は必ずしもナンセンスではない。
エコシステムの形成が進むと、それに伴って最適な要素技術と実現可能なソリューションは変わる。例えば、ユーザが自社サービスに関する何らかの「権利」を他のユーザと取引できるようにしたい場合に、それを仲介するマーケットプレイスを内製するよりも、NFT として実装し OpenSea のような人気のあるサードパーティに出品できる形で提供した方が、流動性などの面でより良い選択肢となる場合はあるだろう。
だがそれも、アプリケーションやサービスがユーザの課題をきちんと解決できてこそだ。率直に言って、自社で NFT を使ったサービスやプラットフォームを展開する場合を除き、現状で提案されてる NFT のソリューションが「顧客が本当に必要だったもの」である場合はさほど多くないのではなかろうか。そんな実態に目を背けたままバズワードとして「NFT」を振りかざしていると、いずれ重大な問題に繋がりかねない。
そうならないためにも、ソフトウェア開発者は NFT のソフトウェア技術としての本質を掴んだ上でソリューションを考えるべきだろう。
今のブロックチェーンやスマートコントラクトを巡る状況は、「Web 2.0」という言葉が叫ばれ始め、Ajax アプリケーションの端緒となった Google Maps などのウェブサービスが自身の機能を Web API として公開し、そうした API をマッシュアップしてサービスに仕立てることが流行りはじめた 2005 年頃と似ている。
言うまでもなく、その際に価値の源泉となっていたのはウェブサービスが提供するユーザ体験であり、Web API を実装して公開することはあくまでマネタイズ手段の一つでしかない。同じように、NFT はブロックチェーンアプリケーション同士の互換性を高めるために用意された API で、何かを NFT 化すること自体が価値を生み出すわけではない。
本来、NFT は所有(モノ)ではなく体験(コト)の文脈に属する話で、ここで必要なのはサービス開発の考え方だ。だからこそ、そのサービスが顧客のどんな課題を解決するか、そして NFT を実装することでエコシステムからどのようなメリットを引き出したいか、そのことをよく考える必要がある。そして、きちんとその過程を経て生まれたソリューションは、もはや「NFT」というラベルを必要としないだろう。
真に DX を実現するには
専門家ではない人々に向けた啓蒙も重要だ。近年、「モノからコトへ」とかデジタルトランスフォーメーション (DX) といったことが叫ばれているにも関わらず、結局は「デジタル所有権」のような「既成の価値観と親和性が高く、分かりやすい」説明が受け入れられる土壌があり、それが NFT を巡る混乱を引き起こしているように思う。
ある種のサイエンス・コミュニケーションとして、一般の人たちに教養として最低限のコンピュータ・サイエンスの知識を身につけてもらえるような活動は、今後ますます重要になっていくだろう。「デジタルには何ができて、何ができないのか」を多くの人が共有している状況になれば、社会の「デジタル化」はより加速していくはずだ。
*1:Ethereum のブロックチェーンは、このようなプログラムを実装しやすくするために「その時点のネットワーク全体の状態(のハッシュ値)をブロックに記録する」方式を採用している。一方で、冒頭に挙げたスライドでは、話を簡単にするため Bitcoin の「その時点で発生した取引をブロックに追記する」タイプのブロックチェーンについて説明している(この辺りの仕組みに興味がある人は "UXTO" で検索してほしい)。この記事では、前者の仕組みを前提として話を進める。
*2:Ethereum 用のスマートコントラクト記述言語 Solidity の場合。内部表現を考えると本来は OOPL でなくてもいいはず。
*3:有名なインシデントとしては、2016 年に、コントラクトの脆弱性をついた攻撃で 50 億円以上が盗まれた The DAO 事件などがある。
*4:逆に言うと、コントラクトの実行は原理的に並列化できないわけで、取引量がさらに増えた時にちゃんとスケールするかは疑問だが…。
*5:日付や時間帯によるが、Ethereum では一回の NFT の取引で数千円以上かかることもザラのようだ。
*6:EIP-721 にも「インスタグラムを参考にした」と書かれている。
*7:フィンガープリントについては、IPFS という P2P ファイル共有システムにアップロードするとハッシュ付きの URI が払い出されるので、それを使うのがベストプラクティスとされている。が、ここまで説明したような技術的背景を理解していない一般の購入者がそれを見分けるのは困難だろう。他にも、IPFS に保存したからといってファイルが絶対に消えないわけではない。
*8:厳密には、これ以前から Ethereum 以外のネットワークで類似のコンセプトが試行されており、それを含めると更に古いものが存在する。
*9:このコードが実際に Ethereum にデプロイされ運用されていることは、Etherscan などのサイトで該当のコントラクトアドレスの情報から確認できる。
*10:もちろん Ethereum ネットワークが存続している限りは、だが。
*11:身も蓋もない言い方をすれば「お金持ちのためのソシャゲ」、ってことになるのだろうか…。
*12:「◯◯を NFT 化しませんか」という案件の勧誘は本当に多いようで、Doge こと「かぼすちゃん」の NFT 案件のように、ネットの片隅で愛犬ブログを開設しているだけの何も知らない一般人にまで声がかかる状況は、正直いかがなものかと思わざるを得ない。
async/await は Promise を置き換えない
まとめ
- async/await 構文は、Promise で書ける処理のうち特定のケースしか表現できない
- 特定のケースとは、ある非同期処理の前処理と後処理がそれぞれ 1 個ずつの場合のみである
- async/await 構文は初心者に非同期処理を導入する際に適しているが、非同期処理を逐次処理として書けるという幻想を与えるので、どこかで知識をアップデートする機会を設けるべきである
この記事はなに?
少しバズったのでまとめておこうかと。
「async/await があれば Promise なんて難しいものは要らない!」とか言ってるウブな子に、複数の API に並列にリクエストを投げて一つ以上成功した時だけ先に進む、みたいな問題を与えて愛でてみたい。
— Yuta Okamoto (@okapies) 2020年12月11日
async/await は Promise のネストを手続き的なコードに見えるように書けるだけで、それ以外の問題には対応できない。そもそも非同期処理は手続きではないので、これが適用できる状況はかなり限定的なのだが、そういう幻想を持っている人は未だに多いと感じる。
— Yuta Okamoto (@okapies) 2020年12月11日
async/await 構文とは?
Promise を使った非同期処理を平易に記述するための糖衣構文。
例えば、Twitter API から指定したユーザのプロフィール画像の URL を取得する関数と、指定した URL のデータをメモリにダウンロードする関数があったとする。どちらも非同期処理なので、一つ前の処理の完了を待ち合わせたり、ネットワークエラーなどに対処する必要がある。JavaScript の場合、これを Promise を使って書くとこのようになる(型アノテーションは TypeScript の記法を流用)。
const fetchProfileImageUrl = (username: string): Promise<URL> => { ... }; const downloadUrl = (url: URL): Promise<ArrayBuffer> => { ... }; const image = fetchProfileImageUrl('okapies').then(url => downloadUrl(url));
非同期処理は、処理が完了する順番やその待ち合わせ、例外処理などの様々なケースを考慮する必要があり面倒が多い。Promise を使えば、非同期処理を「Promise を返す関数」と then の組み合わせで実装できる。
しかし、この例では一つ前の非同期処理の結果を使って処理を順番に実行したいだけなので、組み合わさる処理が増えてくると記述が煩雑になる。そこで、非同期処理を命令型の逐次処理のように書くための構文として async/await が提案されている。以下の例では、fetchProfileImageUrl の前に await キーワードを追加することで、then や catch などの特別なメソッドを使わずに、あたかも非同期処理の組み合わせを逐次処理であるかのように書ける。
const fetchProfileImageUrl = async (username: string): Promise<URL> => { ... }; const downloadUrl = async (url: URL): Promise<ArrayBuffer> => { ... }; const url: URL = await fetchProfileImageUrl('okapies'); const image: ArrayBuffer = await downloadUrl(url);
Promise は多くの言語でクラスやデータ型として表現できるが、async/await は構文の拡張が必要であり、全てのプログラミング言語で利用できるわけではない。非同期処理のユースケースが増える中で、async/await 構文を持つことは新興の言語にとって大きなセールスポイントになっている。
async/await は何ができないか
ある非同期処理について、そこに繋がる前処理や後処理が2つ以上ある場合 (N > 1) は async/await は適用できない。なぜなら、原理的に、二つ以上の非同期処理の並列実行を逐次処理 (N = 1) として記述することはできないからだ。ストリームデータ処理などの文脈では、このような接続関係を fan-in/fan-out と呼ぶ(おそらく論理回路の用語の流用)。

例えば、冒頭のツイートで指摘した問題は投機的実行として知られるテクニックだが、これを解くには、以下のように Promise の配列を Promise.any() に渡す必要がある。*1 *2
const asyncFn0 = async (): Promise<any> => {...}; const asyncFn1 = async (): Promise<any> => {...}; ... const results = [asyncFn0(), asyncFn1(), ...]; Promise.any(results).then(a => { ... });
また、もう少し一般的なユースケースでは「複数の API に問い合わせて、全ての結果が返ってきたら結果を集約して表示する。どれかが失敗した場合はエラー処理をする」というものがある。この場合も、同様に Promise の配列に対して Promise.all() 関数を使う。*3 *4
後処理が複数ある場合も同様だ。例えば、先ほどの問題で Twitter から取得した URL をキャッシュサーバにキャッシュしておくとして、生の Promise を使うなら単に Promise 値 imageUrl に対して then を二回呼べばよい。
const fetchProfileImageUrl = (username: string): Promise<URL> => { ... }; const downloadUrl = (url: URL): Promise<ArrayBuffer> => { ... }; const cacheUrl = (username: string, url: URL): Promise<void> => {...}; const imageUrl = fetchProfileImageUrl('okapies'); const image = imageUrl.then(url => downloadUrl(url)); imageUrl.then(url => cacheUrl('okapies', url));
対して、async/await で書くと以下のようになる。一見、async/await でも正しく記述できているように見えるが、セマンティクスが変わってしまう。つまり、downloadUrl の完了を待ってから cacheUrl しているので並列に実行できず応答性能が劣化する。*5
const imageUrl = await fetchProfileImageUrl('okapies'); const image = await downloadUrl(imageUrl); await cacheUrl('okapies', imageUrl);
async/await をどう教えるか
昨今、「async/await は従来の難しい Promise を完全に置き換える優れたコンセプトである」という主張を散見する。しかし、以上のような限界がある以上、async/await は Promise の特定のユースケースで便利な糖衣構文、という以上のものではない。
Promise が「難しい」のは、そもそも非同期処理が難しいからだ。そして、async/await が「簡単」なのは、非同期処理の中でも簡単な部分をより簡潔に書けるようにしているからに過ぎない。
もちろん、以上のような限界を理解した上で活用するのは問題ない。特に、JavaScript のように代表的なユースケースに UI 処理やネットワーク処理などが入ってくる環境では、プログラミング入門者向けに非同期処理の必要な部分で async/await 構文を「おまじない」として教えるのは致し方ない面もある。
だが、そうした便宜上の教え方を真実と勘違いした技術者が増えるとなると話は別で、コミュニティが主体となった知識のアップデートなど、何らかの対策が必要であるように思う。
十年以上前、Protocol Buffer の RPC 機能(今日 grpc として知られているもの?)の是非について論争があった際に、反 RPC 派の Steve Vinoski 氏が以下のように述べたという。当時と比べて開発環境は大いに変化したが、残念ながら、根本的に問題になっている点はあまり変わっていないように思う。
For years we’ve known RPC and its descendants to be fundamentally flawed, yet many still willingly use the approach. Why? I believe the reason is simply convenience. Regardless of RPC’s well-understood problems, many developers continue to go down the RPC-oriented path because it conveniently fits the abstractions of the popular general-purpose programming languages they limit themselves to using. Making a function or method call to a remote or distributed function, object, or service appear just like any other function or method call allows such developers to stay within the comfortable confines of their language. Those who choose this approach essentially decide that developer convenience and comfort is more important than dealing with hard distribution issues like latency, concurrency, reliability, scalability, and partial failure.
補足
記事に対していただいたご意見など。
async/await の明確なメリット
ひとつは、スタックトレースの取り扱い。async/await構文は、クロージャーを使って実現するより効率がよく、スタックトレースのサポートもよりよいため、便利な糖衣構文以上の利便性をもたらす。https://t.co/ntwGWO4My0
— Ryusei (@mandel59) 2020年12月13日
まあ、これは論の主旨への反論ではなくて、「糖衣構文」という説明の不正確さをつついてるだけですね。
— Ryusei (@mandel59) 2020年12月13日
スタックトレースという考え方自体が、古典的な制御構造を背景にしているとは思います。
制約があるということは、処理系の側で制約を使った最適化ができるということなので、async/await を使えるときは使った方が良いというのはその通りですね。
追記:
async/awaitは、「Promise を使った非同期処理を平易に記述するための糖衣構文」ではなく、「古典的な制御構造を非同期処理に埋め込むための構文」と捉えるべきではないかと思います。
— Ryusei (@mandel59) 2020年12月13日
async/awaitと言うから、こいつらが重要に思えてしまうけど、本当に重要なのは、async関数に埋め込まれたlet文だとかwhile文だとかfor文とかtry/catch文の方です。
— Ryusei (@mandel59) 2020年12月13日
非同期処理にも古典的な制御構造は出現するけど、whileもtry-catchも新しく非同期版のセマンティクスを持つものを用意しないといけない。async/awaitを使えば、古典的な制御構造を、構文をそのままに、非同期処理でも使い回すことができる。
— Ryusei (@mandel59) 2020年12月13日
これは完全におっしゃる通りですね。Promise を使っていると変数間の依存関係を常に意識させられて煩雑な面がある(良い面もあるにせよ)わけですが、古典的な制御構造の範囲内では、そこを処理系がよしなにしてくれる。
fan-out でも Promise.all を使う
const imageUrl = await fetchProfileImageUrl('okapies'); const result = await Promise.all([ downloadUrl(imageUrl), cacheUrl('okapies', imageUrl), ]);
ありがとうございます。まず、何をもって「Promise を置き換えた」と判断するかは様々な見解がありうるという前提を置いた上で、僕は Promise.all() に渡す式を評価すると Promise の配列が出てくる以上は Promise を隠蔽できていないと考えます。
これに対して、all や any などの関数は async/await に付随した特殊な専用構文であり、await していない async 式を渡せる例外とみなすことは可能だと思います。しかし、この解釈だと関数呼び出しを書く場所が制約されてコードの取り回しが悪くなりますし、それならば Promise を変数として直接取り扱った方がシンプルかつ楽な方法に見えます。
あと、okazuki さんご自身も注釈されているように、Promise.all() は渡した Promise のうち一つでも失敗すると全体が失敗します。たとえば、キャッシュサーバへの通信経路が輻輳して URL のキャッシュが失敗すると、たとえ画像のダウンロードは成功していても一緒に失敗とみなされます。そこで、記事では個々の async 関数の中でエラー処理をすることで Promise.all() に例外を見せない方法を提案されていますが、それはそれでエラー処理の方法が制約されることになります(上のレイヤに例外のハンドリングを移譲する、など)。
JavaScript の場合、代わりに Promise.allSettled() を使う方法があるかもしれません。これを使うと、渡した非同期処理が一部失敗することを許容して、全て「完了」するのを待つことができます。ただこの方法でも、全体の完了時間が、渡した非同期処理のうち最も完了まで時間がかかったものに律速されます。これを避けたいなら、やはり個別の非同期処理ごとに then を書くしかないように思います。
all を使う方法がうまく行かないのは、おそらく all が集約関数だからだと思います。並列処理を逐次処理の中で書けるようにするには処理を集約するしかないですが、その代わりに個別の事情に沿った処理ができなくなってしまうのです。
any を race で代替できるか
ブコメより。
anyはexperimentalでも、raceで代替できるはず。/ thenの代替をawaitでやりたい、というモチベーションなら、raceで最初のひとつを待ってから処理した後、処理済みのpromiseを除いてからもう一度raceにかけてawaitすればいい。
雑に書いてみたんですが、reject されると promise ではなく error が渡ってくるので、失敗した Promise を特定する方法が無さそうです。例外に自分自身の参照を埋め込むしかなさそう。
let resolved = null; let results = [promise1, promise2]; while (!resolved) { try { resolved = await Promise.race(results); } catch (error) { results -= ???; } }
*1:なお、any 関数は現時点では experimental なので Edge などのブラウザでは使用できない。
*2:追記: any は race 関数 で代替できるというコメントを頂いたが、race は最初に完了した Promise が rejected だった場合は、それ以降に fulfilled で完了する Promise があっても rejected になる。つまり、セマンティクスが異なるので置き換えられない。
*3:追記: TC39 で提案されている await.ops を使えば Promise をユーザに見せずに済む、というコメントを頂いているが、僕はこれは論旨に影響しないと考える。なぜなら、仕様書を読む限り、結局は Promise の配列を受け取って Promise.all() 等の集約関数にそのまま引き渡す薄いラッパーに過ぎないからだ。他の懸念点としては、例えば Promise が一つではなく二つ以上成功した場合を扱うユースケースがあった時に、仮に any2() という関数を生やすとして、それを毎回言語仕様に反映するのか、ということだ。
*4:追記: この記事で問題にしているのは、Promise という文字列をユーザが書かずに済むか否かという話ではなく、計算を記述するパラダイムの根本的な違いについてだ。本文中では説明を端折っているが、本質的に Promise は有向非循環な非同期計算の計算グラフ (DAG) を直接組み立てる API であり、その帰結として、N > 1 の場合は命令型のパラダイムでは記述できない。async/await で記述できるのは N = 1 の場合のみだ。これは原理的な問題なので、構文の工夫では解決できないと考える。
*5:もし処理系が Promise 同士の依存関係を正しく分析できるなら、Promise 版と同等のコードを生成してくれるかもしれない。その場合、コード上は逐次処理に見えるのに実行順序がひっくり返る、というようなことが起きるが…。
コロナ時代の VR 音楽イベント・ガイド
コロナ禍の折、皆様はいかにお過ごしだろうか。僕は、所属先の業務の多くがリモートでも遂行可能なこともあり、2月中旬からずっと家で仕事をしている。しかし、もちろん弊社は非常に幸運な例であり大きな影響を受けている業界も少なくない。
その一つが、僕も折りに触れて参加している商業音楽イベントだ。先日、ようやく緊急事態宣言が解除されたとはいえ、感染者数は一進一退であり、いわゆる「三密」の象徴とも言えるライブの類は当分難しいだろう。
そのような情勢を反映して、音楽業界では YouTube などの動画配信プラットフォームを使った音楽イベントのオンライン化が数多く試みられている。今のところは収益度外視、あるいはチャリティ名目というものが多いが、事態の長期化はほぼ間違いない以上、CD 売上の減少に伴ってライブビジネスへ転換を進めてきたと言われる音楽業界にとって、ビジネスモデルの面で新たなチャレンジを強いられることになる。
←今年 去年→#SecondSky pic.twitter.com/LyLXW3HqWM
— Noriyuki IMAMURA (@n_ckl) 2020年5月10日
そもそも、我々は「ライブという体験」に何を求めてチケット代を払い、わざわざ会場へ足を運んでいたのだろうか? そして、オンラインで同じ価値を実現するには何が必要だろうか? この一ヶ月ほど、いくつかのオンラインライブを視聴する機会があったので、個人的に考えたことをまとめてみたい。
目次
動画プラットフォームの活用
コロナ禍で self-quarantine を余儀なくされているファンに向けて、自分のパフォーマンスを配信しようとしたアーティストが直面したのは、そもそも「会場が使えない」という問題だった。よって、ジャニーズのようにコロナ流行前から会場を押さえていた場合を除いて、自宅での収録が基本となる。
例えば、この B'z のパフォーマンスでは、各自が収録した演奏を編集で組み合わせることで、国内外のメンバーとの「おうちセッション ("HOME" session)」を成立させている。
また、このような事前に収録した動画の配信だけでなく、ストリーミング配信によるイベントも盛んに行われている。
例えば、世界最大規模の EDM フェス Tomorrowland のオンラインイベント "United Through Music" では、DJ 達のパフォーマンスが YouTube 上でライブ配信され、観客はチャット上でリアクションを返すことができた。また、本イベントは Zoom 経由でも参加でき、家のカメラの前でノリノリで聴取している「観客」たちの様子を共に配信するといった工夫も盛り込まれている。
あと、少人数なら「密」ではないということか、EDC 主催の "Virtual Rave A Thon" では、自宅ではなく無観客のスタジオを使用していた。この場合、高価な機材やライティングが使用できるので、より「非日常感」を演出しやすい。
youtu.be(個人的には、この Z-Trip の職人芸の光る DJ プレイがとても良かった。初っ端から司会者の直前の音声をミックス素材化し始めて楽しい)
日本でも、秋葉原の MOGRA が Twitch で無観客の配信を続けている他、いくつかのクラブが配信のみの営業を行っている。
仮想空間でのライブ
このように、YouTube や Twitch などの配信プラットフォームの普及により、コロナ以前から、配信者−視聴者間の「チャット」や「スパチャ(投げ銭)」を介したコミュニケーションがすでに一般的なものになっていたことは、ライブのオンライン化にとって幸運だったと言える。
しかし、我々が「ライブ」という非日常的な体験に求めているのは、単に好きなアーティストの演奏を聞いて楽しむということだけではなかったはずだ。それは例えば、光と音の洪水に投げ込まれる「没入感」だったり、隣の観客と一緒に歓声を張り上げ、歌に合わせて腕を振り上げる「一体感」だろう。
このことから、自宅に居ながらにしてあたかもライブ会場にいるかのような感覚を与えることができる、仮想空間プラットフォームを活用するアイデアが出てくるのは自然だと言える。今回のコロナ禍に対応して、既存のオンラインゲームを活用したものから専用の VR プラットフォームに至るまで、様々な試みがされている。
興味深いのは、「会場」というハコの捉え方からそこでの「観客」の位置付けに至るまで、イベントによって実に様々なアプローチがなされていることだ。以下では、いくつかの取り組みを紹介していきたい。
会場を仮想世界に写し取る
Blockeley は、コロナにより卒業式が不可能になったカルフォルニア大学バークレー校 (UC Berkeley) の学生たちが、仮想空間で卒業式を開催するため、Minecraft の中で敷地と校舎を再現するというプロジェクトだ。完成した校舎は、学外からも Minecraft クライアントでアクセスできる。当日は、学長が自身のアバターで参加して式辞を読み上げたようだ。
また、同時に卒業記念パーティーとして、世界各国から招聘した DJ によるバーチャル音楽フェスが開催された。もちろん同様に、実際のフェス会場を模してDJ ステージや照明が完備されたスタジアムが Minecraft 内に用意された。
音楽イベントの仮想化という点で見ると、Blockeley は最も基本的な形と言えるだろう。つまり、現実のフェス会場のレイアウトをそのままモデリングしたものになっている。観客は観客席でジャンプやエモートで盛り上がり、演者はステージに上がって音楽を流す。また、観客はステージに進入できないようになっており、観客席とシステム的に区別されている。
「第四の壁」を取り除く
ステージと観客席を区別して配置するモデリングは、現実の会場レイアウトを反映しており分かりやすい。しかし、この区別は本質的なのだろうか? つまり、物理世界で興行をトラブルなく進行するための運営上の制約に過ぎないのでは、ということだ。例えば、ステージに興奮した観客がなだれ込んだら演奏どころではなくなる。大勢の人間を一箇所に集めた際の警備をどうするか、というのは、現実のイベントでは大きな問題だ。*1
一方で、仮想空間のイベントではそのような問題はない。いや、ないわけではないが、その負担は大いに軽減される。興奮した客に楽器をひっくり返されたくないなら、主催者はそういう「コード」を実装すれば良い。あるいは、厄介な客をつまみ出すために警備員を雇わずとも、ワンボタンでミュートするなり BAN するなりすれば済む。もし、仮想空間への移行によって運営上の問題が解決され、ステージと観客席を分け隔てる必要がないのなら、もはや第四の壁は存在しない。
例えば、4月末に VRChat(VR ヘッドセットを使うソーシャル VR アプリの一つ)内で開催されたこのライブイベントでは、途中で会場がライブハウス風の場所から「電脳空間」へとまるごと切り替わる。ここでは、ステージと観客席の区別が取り払われ、観客はステージの「中」で演者のパフォーマンスを体験することになる。
他にも、有志が開発した DepthField という仕組みを使い、サテライト会場なのに VR の中でメイン会場の VR が体験できるなど、先鋭的な仕組みがいくつも取り入れられていたようだ。
youtu.be(演奏は 1:29:00 あたりから)
これは有志による非商業的なものだが、もっと大規模かつ商業的に行われたものもある。人気バトロワゲーム「フォートナイト (Fortnite)」内で行われた音楽イベントも、仮想空間でのライブパフォーマンスについての興味深い取り組みの一つだ。公式発表によれば、本イベントは同時接続数が 1,230 万人に達したという。以下の記事によれば、収益面でも大きな成功を収めたようだ。
もともと、フォートナイトはシューティングゲームでありながら「建物を建てながら銃で撃ち合う」というゲーム性から、大量に用意された3Dモデル部品を組み合わせてプレイヤー自身が自由なマップを作れる「クリエイティブモード」を提供するなど、仮想空間プラットフォームとしての機能を備えている。この特性を活かしてか、フォートナイトは昨年にも世界的人気 DJ マシュメロをゲストとして同様のイベントを行っていた。
この時は Blockeley と同様の「舞台−観客席」形式だったが、人気ラッパートラヴィス・スコットを招いた今回のイベントでは、その取り組みをより進化させたものになった。イベントは、マップ全体がステージとなった広大な会場に、巨大な「神」と化したトラヴィス・スコットが観客を蜘蛛の子のように吹き飛ばして登場するのを皮切りに、曲に合わせて場面が次々と切り替わっていき、最終的に宇宙にまで達する。
このイベントは、現時点のこの種の取り組みとしては、最も完成度の高いものと言ってよいだろう。以下の動画は、実際にプレイしていなくても、その面白さを十分に楽しむことができるものになっている。
観客の抽象化
前節ではステージと観客席の融合について見てきたが、ライブ会場のモデル化については、それ以外にも様々な切り口があるように思う。その一つは「観客をどう表現するか」ということだ。その具体例として、個人的に大ファンである DJ のポーター・ロビンソンが主催した Secret Sky を取り上げたい。
これは、YouTube や Twitch 上で、ポーターが直々に指名した19組のアーティスト達が入れ替わり立ち替わり、14時間に渡って自宅などから DJ セットをプレイするという企画。当日の様子については以下の記事が詳しい。
ポーターは、以前の記事でも紹介したように、アニメ好きが高じすぎて日本の大手アニメスタジオと組んで新曲のミュージック・ビデオを作ってしまうほど日本のオタク文化やサブカルに造詣が深く、この日の参加アーティストにも3人の日本人(kz、長谷川白紙、キズナアイ)が含まれていた。また、彼自身のセットでも序盤から ICO のBGM や「ちょびっツ」OPテーマ曲をシレっと放り込むなど、フリーダムな選曲センスを遺憾なく発揮。
さて、本題だが、Second Sky ならではの取り組みとして、動画配信と並行して Web 上に VR 会場を用意したことが挙げられる。まず、下記のツイートの動画を見てほしい(音出し推奨)。
Last Saturday we launched a virtual music festival called Secret Sky with @porterrobinson. Over half a million attendees from all over the world came through the digital auditorium during the 14-hour show. Here some highlights. #secretsky #webgl pic.twitter.com/bVtBkAvKts
— Active Theory (@active_theory) 2020年5月12日
つまり、観客はアバターではなくサイリウムなのだ。確かに、会場自体は「舞台−観客席」のモデリングを採用しており、なんなら VIP エリア(会場後方の坂の部分)まで備えているが、しかし、ここには「観客とは自己表現する主体ではなくサイリウムである」という圧倒的な割り切りがある。そして、互いの動作はサーバを介してリアルタイムに同期されているので、自分を操作することで「みんなでサイリウムを振る」こともできる。
この VR ライブ会場は、アメリカのクリエイティブ集団 Active Theory が開発した技術を用いて実現された。ライブ会場のサイトはすでにクローズしているが、彼らはポーターの新作アルバム "Nurture" の PR サイトの制作にも関わっており、ここでほとんど同じものを体験できる。これも Secret Sky と同様に自分の操作がオンラインで同期されるので、たまたま同時にアクセスしている人がいれば(左下の表示が CONNECTED になる)、一緒に仮想空間を飛び回ることができる。*2
この仕組みの興味深い点は、WebGL で実装されているので、スマホを含む現代のモダンな Web ブラウザでならまず動くということだ。また、観客は単なる線なので、多数の観客を収容しても高価な GPU は必要ないし、何ならスマホやタブレットからもアクセスできる。つまり、ゲームなどの専用クライアントを必要とする他の方式と比べて、圧倒的に多くのファンにリーチできる。*3
ライブの臨場感とは、揺らめくサイリウムだったのかもしれない。
— 多々良 タツキ (@char_omni) 2020年5月10日
ユーザーの抽象化=サイリウム。描画が楽。集まると綺麗。ジャニーズ無観客ライブでも重要視されていた印象。
「光の線」の自己同一性は相当低いけどwebインタラクションで自己帰属感を持たせているのが技アリ。
うまい!#SecretSky pic.twitter.com/1epqtnsjxT
音楽イベントの本質とは何か
この記事で挙げた二つの論点、つまり「ステージと観客席の融合」と「観客の抽象化」*4は、どちらも「多人数が参加するイベントにおいて必然的に発生する物理的制約とどう向き合うか」という議論に関係している。
前者は、会場レイアウトを制約していた「イベント警備」が必要でなくなった時に起こりうる変化を示している。これは、今まで制約に縛られてきたクリエイティブな想像力を解き放つ土壌となるに違いない。一方で、後者は「観客側のデバイスが積んでいる GPU 性能」という、短期的にはいかんともしがたい制約をどう解くかということだ。
特に後者については、なかなか難しい問題を孕んでいる。VRChat をやると分かるのだが、作り込まれた 3D モデルやアバターが存在する仮想空間にアクセスすると、あっという間に GPU メモリが悲鳴を上げ始める。なので、上で紹介した VRChat のイベントを見ると分かるのだが、この手の大人数のイベントでは観客を強制的に「手」とか「カカシ」にする運用になっているようだ。それでも、同じ空間に数百人を詰め込むのは難しいのではないかと思う。
これは、自己表現の一環として、自身のアバターを装飾する 3D モデルを互いに売買することでクリエイターを中心とした経済を駆動することを狙っている、多くの VR プラットフォームのビジネスモデルとは率直に言って矛盾してしまう。3D空間を使ったオンラインフェスが、Minecraft やフォートナイトなどの既存のゲームをインフラとして使っているのは、ゲームをやるような人間は強い GPU を持っているということもあるだろうし、他にもあらかじめ最適化が施されたモデルを使わないと現実的な性能で描画できない、という話もありそうだ。*5
だから、できるだけ多くの観客に一体感を共有してもらうことを重視するなら、Secret Sky の方式はかなり正解に近いのではないかと思う。例えば、これにワンボタンでエモートできる機能とか音声入力の機能を持たせたりすると、かなり面白いことができそうだ。
一方で、ある種の参加者にとってライブは自己表現の場でもある、というのも事実である。そうでなければ、誰も色とりどりのフラッグを持ち込んだり凝ったペイントをして臨んだりはしないだろう。だとするなら、真に必要なのは、あらゆるご家庭にプレステ5や NVIDIA の高性能 GPU を積んだテレビを配ることなのかもしれない。
現在は、オンラインイベントにとって、あらゆる意味で過渡期であることは間違いない。音楽ファンの一人として、業界を盛り上げるようなとびきり面白いアイデアが出てくることを期待している。
*1:Wikipedia の「興行」の項目では、芸能界とヤクザが結びつきやすい背景として「狭い区域にたくさんの観衆を集めるという構造上の特質から、暴力による妨害に弱いため、古くから不良を手なずける意味もあって、ヤクザ者・暴力団との腐れ縁があり、またヤクザ自身が興行を手がけることも多かった。」という解説がある。
*2:この方式について、このツイートでは「風ノ旅ビト」というゲームの影響を示唆している。ちょっと調べてみた限りでは、たしかに同じセンスを感じる。
*3:当日は、観客が殺到したことで Google Cloud に DDoS 判定されてアクセス拒否されたりとか、色々あったみたいだが…w
*5:この辺りのチューニングについてはあまり詳しくないのだが。
Apple/Google が開発中の接触者追跡 API を調べた
先日はシンガポール政府が開発した接触者追跡技術 "BlueTrace" について調べたが、今日は引き続き、Apple と Google が共同開発中としている Contact Tracing API について調べてみる。
そもそも、現状では iOS 上での制限により実用レベルで Bluetooth ベースの接触者追跡技術を実装するのは難しく、Apple の対応待ちという状況であるため、事実上、本 API が本命になると予想する。
アーキテクチャの概要については下記のツイートに掲載されている図が分かりやすいので、この記事ではもう少し細かいところを見ていくことにする。読み違えている部分があるかもしれないのでツッコミ歓迎。
Google + Apple が提供する、COVID-19 の Contact Tracing(コンタクトトレーシング)の仕組みを図にまとめました。 pic.twitter.com/rwoGtiDofy
— 太田 祐一 (@yuichiota) 2020年4月13日
中央サーバ方式の問題点
Apple/Google が提供する Contact Tracing の最も大きな特徴は、接触者の探索をサーバではなくクライアント端末上で行うことだ。
BlueTrace では、接触者調査員 (Contact Tracer) がコロナ陽性と診断されたユーザの濃厚接触者を発見するために、一度、端末内の接触履歴を(本人の承認を得た上で)保健当局のサーバにアップロードさせ、サーバ上で履歴にある ID を保健当局のみがもつ暗号鍵で復号して接触者の電話番号を得るようになっている。
この方式は、調査の網羅性という点では優れているが、懸念すべき点がないわけではない。例えば、以下のようなケースが思いつく:
- いわゆる「夜の街クラスタ」では聞き取り調査が難航し、クラスタ対策において大きな障害になったと言われる。これは、店側や客側が「特定の客が高級クラブや風俗店に出入りしていること」を隠そうとしたのが原因と言われている。このような状況においては、自分や接待相手の素性が明らかになると困る層は、やはり自分のスマホへの Contact Tracing アプリのインストールを忌避するだろう
- 接触履歴のアップロードに端末の所有者の同意が必要な手順になっているとはいえ、当局が「誰が誰と会っていたか」という情報を容易に入手可能な仕組みであることに変わりはない。例えば、一部の国家が自国民や旅行者に対して「感染症対策」の名目でアプリを常に起動することを求め、感染の有無に関わらず、接触履歴の提出を事実上強制するような「運用」がなされる可能性は否定できない
Diagnosis Key による非中央集権的な接触者検出
一方で、Apple/Google が提案するシステムにおいては、コロナ陽性と診断されたユーザは、端末に蓄積された接触履歴はアップロードせずに、代わりに Diagnosis Key(診断キー)のみをサーバにアップロードする。
あとで説明するように、Diagnosis Key は各ユーザを一意に識別する Tracing Key から算出されるが、逆に Diagnosis Key から Tracing Key を算出することはできない。また、Diagnosis Key は毎日更新される。つまり、第三者は Diagnosis Key からユーザを特定することはできない。
接触者検出は、サーバではなくユーザの端末の中で行う。端末に蓄積した接触履歴はこのために(のみ)使われる。ユーザ端末にインストールされたアプリは、保健当局のサーバから陽性確認されたユーザの Diagnosis Key の一覧をダウンロードして、それを端末の Contact Tracing API に渡して曝露検出 (exposure detection) を要求する。API は、渡された Diagnosis Key に対応する接触履歴の有無をアプリに対して回答する。
最終的に、コロナ陽性者との接触があったと判定された場合は、アプリを通じて保健当局に申告を行うことになると思われる。
接触履歴に対するアクセス制御
もう一つの特徴は、どうやらアプリ自身も端末が蓄えた接触履歴に自由にアクセスできるわけではない、ということだ。仕様書によると、Contact Tracing API が提供するメソッドは以下である:
CTStateGetRequest/CTStateSetRequest- デバイスの Contact Tracing 機能のオン・オフを制御する
CTExposureDetectionSessionCTSelfTracingInfoRequest- ユーザの認可を経た上で、端末から Daily Tracing Key (Diagnosis Key) を取得する
つまり、接触履歴はベンダーが提供する Contact Tracing Framework の内部で管理されており、アプリがユーザの許可なしに Diagnosis Key を取得してアップロードすることはできない。また、接触履歴にアクセスできないので、アプリ側で「誰と誰が会っていたか」という情報は取得できない。
このことから、スマホ OS ベンダー提供の Framework は接触履歴の蓄積と検索を担当し、保健当局が提供するアプリは Diagnosis Key 広告サーバとの通信や、接触者の相談窓口への誘導を行うといった役割分担が想定されているようだ。
鍵の生成とローテーション
Contact Tracing Framework で使う鍵は、鍵の更新期間ごとに左から右へ導出される。逆に、右から左へ遡って算出することはできない*1。
Tracing Key → Daily Tracing Key(1日毎) → Rolling Proximity Identifier(10分毎)
Tracing Key は、ユーザ(端末)を一意に特定する鍵で、暗号論的乱数生成器 (CRNG) で生成した 32 バイト (256-bit) の値、とされている。仕様書では "securely stored on the device" とされているので、おそらく端末内にある暗号鍵保管用の耐タンパ性チップに保存されるのではないか。その場合、Tracing Key は端末の所有者自身も確認できない。
Daily Tracing Key は、Tracing Key と Day Number から日替わりで生成される 16 バイト (128-bit) の値。コロナ陽性と診断された場合は、生成した Daily Tracing Key の一部(過去14日分)を Diagnosis Key として保健当局のサーバへ提出する。
Rolling Proximity Identifier (RPI) は、Daily Tracing Key を秘密鍵として、1 日を 10 分単位で分割した値である Time Interval Number を HMAC 関数に適用して得られる値。この値を、Bluetooth を通じて他の端末と交換して端末内に蓄積する。Bluetooth 通信の際、匿名性を保つために MAC アドレスはランダムなものを使うが、MAC アドレスと RPI は常に一緒に更新する。
すでに説明したとおり、10 分間のみ有効な RPI から Tracing Key は逆算できないため、この値を Bluetooth で放送 (broadcast) しても個人は特定できず匿名性は保たれる*2。
端末で曝露検出を行う際は、各端末はサーバから取得した Daily Tracing Key を使って、可能性のある Time Interval Number に対して総当りで RPI を計算し直し*3、端末内に保存された RPI との一致を見ることで、コロナ陽性者との接触の可能性を判定する。
まとめ
そしてもう一つはコロナ禍後の社会のヴィジョンがほとんど語られないことだ。コロナは人類全体を滅ぼすほどのウイルスではない。ほとんどのひとは生き残る。そのときどんな社会を残すかも考えるべきである。いまマスコミでは命か経済かと選択を迫る議論が多い。でも本当の選択は「現在の恐怖」と「未来の社会」のあいだにもある。こんな監視社会の実績を未来に残していいのか。
東浩紀「緊急事態に人間を家畜のように監視する生権力が各国でまかり通っている」 〈AERA〉|AERA dot. (アエラドット)
Apple/Google の Contact Tracing システムは、BlueTrace と比べると若干複雑な仕組みだが、「どこで会ったか」という情報だけでなく「誰と誰が会ったか」という情報を明らかにせずともコロナ陽性者との接触を検出できるなど、プライバシー保護の面では多くの点で BlueTrace より優れているように見える。
当局が接触者を検出する手段はあくまでアプリを通じた各自の自己申告による、という点がデメリットだが、裏返せば、先に論じたように「夜の街クラスタ」のような人たちが導入する際の心理的抵抗を減らせるという意味ではメリットになりうる。
一方で、プライバシーの担保が Contact Tracing Framework に多くを依存しており、ここにセキュリティホールがあると多くの前提が崩れることになる*4。また、アプリが独自に位置情報や近くにいるユーザの情報を集めていないかにも注意する必要がある*5。Apple/Google が提供するから安心とするのではなく、設計で期待されている要件が実装においても達成されているかは、我々第三者による十分な検証が必要だろう。
BlueTrace: シンガポール発のコロナ接触者追跡アプリ
今日、コロナウィルスの濃厚接触者を把握するためのスマホアプリの導入を政府が検討しているという報道が出た。
何日か前に、コロナ対策専門家会議でクラスタ対策を主導している西浦教授から以下の発言が出たように、感染症の専門家からも、医学的な検査を補完する手段としてスマホによる電子的な接触者追跡を活用したいという期待があるようだ。
日本でもやりたいのですが、皆さん許してくれますか。 https://t.co/7YFWwkTnBi
— Hiroshi Nishiura (@nishiurah) 2020年4月8日
この報道でも言及されているように、これはシンガポールの政府機関の一つ Government Technology Agency (GovTech) がコロナ感染者の接触者追跡のために開発した TraceTogether を日本向けに改修して利用するという計画らしい。
調べてみると、彼らはつい数日前に、TraceTogether のクライアント・サーバ間プロトコルを BlueTrace と名付けて仕様化すると共に、参照実装である OpenTrace をオープンソース化していた。OpenTrace には、iOS および Android 向けのクライアント実装と、Node.js ベースのサーバ実装が含まれており、すぐに利用できるようになっている。
一方で、当局主導で行われる個人の行動追跡はプライバシーの観点で大きな懸念がある。いま、単に「プライバシー」と書いたが、公権力である国家による行動追跡は、民間企業によるそれと比べても数段階上の配慮が求められる。万が一、目的外使用に繋がることがあれば、民主主義国家である日本に別種の危機を招き寄せることになりかねない。
この点に関して、BlueTrace は「ユーザのプライバシーを守りながら接触者追跡を行う」と謳っている点が大きな特徴である*1。具体的には、BlueTrace は接触者追跡にあたって GPS などの位置情報を使わない。代わりに、至近距離に存在するスマホ同士で Bluetooth を介して一時 ID を交換し、各端末のストレージに蓄える(かつてのすれちがい通信と類似の仕組みと思われる)。そして、所有者の感染が明らかになった段階で、本人の承認を経てスマホに蓄積した一時 ID をサーバ側へと送信し、履歴に含まれる ID の該当者へ警告を行う仕組みになっている。
また、同様の仕組みは、Apple と Google が共同で開発している Bluetooth ベースの接触者追跡システムでも採用予定だとされている。
では、これらの仕組みは本当に設計者たちの期待通りにプライバシーを守りつつ、接触者追跡という目的を十分に達成できるだろうか? 幸い、BlueTrace の設計者たちはこれらの技術的詳細を論文やソースコードとして公開しており、外部の技術者が検証できるようになっている。この記事は、BlueTrace の技術的な紹介を通じて、今後数週間のうちに大きなトピックになるであろう「スマホを利用した接触者追跡」についての議論を喚起することを狙いとしている。
よく、「技術は政治や思想から自由である/あるべきだ」という主張がなされることがあるが、本件はそれに対する最も明瞭な反例と言えるだろう。特に、この接触者追跡技術については、公共政策、感染症学、そしてソフトウェア技術という、従来はなかなか交わることのなかった領域を跨いだ総合的な視点が必要だ。ソフトウェア技術者のコミュニティは、今後始まるであろう議論に備えておくべきだと思うし、それが我々の専門家としての「社会的責任」を果たすこと繋がると思う。
BlueTrace とは何か
BlueTrace のトップページから引用する:
BlueTrace とは?
接触者追跡 (contact tracing) は、COVID-19 に代表される感染症の蔓延を減らすための重要なツールです。 BlueTrace は、Bluetooth デバイスを用いて、プライバシーを保護しながらコミュニティ主導の接触者追跡を行うプロトコルであり、グローバルな相互運用性があります。
BlueTrace は、非中央集権的な近接ロギング (proximity logging) を、公衆衛生当局による中央集権型の接触追跡で補うように設計されています。 Bluetooth による近接ロギングは、手作業の接触者追跡の限界、すなわち個人の記憶に頼るため、知り合いや会ったことを覚えている接触者しか追跡できないという課題を解決します。すなわち、BlueTrace により、よりスケーラブルかつ少ないリソースで接触者追跡が可能になります。
BlueTrace はプライバシーを中心に設計されています
#1: サードパーティは BlueTrace 通信を使用したユーザの継続的な追跡はできません
デバイスの一時 ID を頻繁に変更 (rotate) することで、悪意ある参加者が BlueTrace メッセージを傍受して個別のユーザを継続的に追跡するのを防ぎます。
#2: 個人を特定可能な情報の収集を制限
個人を特定可能な情報として収集されるのは電話番号のみです。これは保健当局によってセキュアに保管されます。
#3: 遭遇履歴はローカルストレージに
各ユーザの遭遇履歴 (encounter history) は、ユーザ自身のデバイスにのみ保管されます。保健当局がこの履歴にアクセスできるのは、感染者が履歴を共有することを選んだ場合のみです。
#4: 同意は取り消し可能
ユーザーは自分の個人データを管理できます。ユーザが同意を撤回すると、保健当局に保存されている個人を特定可能なデータはすべて削除されます。これにより、すべての遭遇履歴はユーザーにリンクされなくなります。
BlueTrace プロトコルは OpenTrace コードを用いて実装できます。 TraceTogether は 2020/03/20 にシンガポールでローンチしました。これは、世界初の国家的な Bluetooth 接触者追跡アプリであり、OpenTrace コードを用いて BlueTrace プロトコルを実装します。
BlueTrace 技術の詳細
政府指導者や政策立案者向けの資料では、より具体的な仕組みが説明されている:
- ユーザ登録時に電話番号を提供すると、保健当局のサーバはそれをランダムな User ID と結びつける
- アプリが生成する一時 ID は User ID を暗号化したものであり、保健当局のみが復号できる
- アプリをインストールした端末間で Bluetooth 通信が確立された場合、BlueTrace プロトコルにより一時 ID、携帯の型式、電波強度の3つを記録する
- ユーザの感染が確認された場合、保健当局の接触者追跡員はユーザに PIN を提供する(スクリーンショットでは6桁)
- ユーザはアプリに PIN を入力することで、過去21日分の接触履歴のアップロードに同意する
- 接触者追跡員は(一時 ID を復号して?)得た電話番号を用いて接触者へ連絡する
- アプリは、Bluetooth をオフにしていない限り、バックグラウンドで周囲の Bluetooth デバイスをスキャンし続ける
- ただし、現状では iOS はバックグラウンドの Bluetooth デバイススキャンを許可していないので、常にフォアグラウンドで起動する必要がある。ただし、Wired の記事によれば、Apple はこの制限を近日中に撤廃する方向で動いている模様
だが、こうしたBluetooth方式の追跡システムは、これまで大きな壁に直面していた。アップルがiOSに制限をかけることで、バックグラウンドで稼働するアプリがBluetoothを無制限に利用できないようにしていたのだ。これはプライヴァシーの保護と省エネルギーを考慮した措置だった。
ところがアップルは今回、濃厚接触を追跡するアプリに限ってその規制を撤廃する。アップルとグーグルはスマートフォンのバッテリー駆動時間を考慮して、最小限度の電力しか使わないようにするという。「このアプリは24時間ずっと休むことなく稼働するので、消費電力を徹底的に抑える必要があります」と、共同プロジェクトの広報担当者は説明している。
- データ解析ダッシュボードについては、調査員や医療専門家と協同しながらプロトタイピングを進めている
- 各国の BlueTrace 互換アプリ同士で接触者情報を共通に収集できるようにしたい。これにより、国境を跨いだ接触者追跡が可能になる
白書
より技術的詳細について書かれた白書(white paper)が公開されている。
まとめ
white paper やソースコードについても紹介したかったが、もう午前2時なので機会があれば後日ということで。
ざっと眺めた感想としては、要素技術はなかなか興味深いと思う。Apple/Google が同様の技術を採用する方向で動いているということで、この方式がスタンダードになっていくのかもしれない。
ただ、一つ注意しておきたいのが、そもそもこの仕組みが接触者追跡という目的に対して十分に効果を発揮するかはまだよく分からないということだ。それは、彼らのドキュメントの中でも明確に宣言されている。プライバシー上の大きな懸念を呼ぶシステムである以上、その辺も含めて検証が必要だろう。
また、なんとなくだが、収集された情報の利用については技術面というより法律面、運用面での制約を加える必要を感じる(まず思いつくのは、特定の地域に「任意の第三者」がビーコン収集端末を並べて監視カメラと突き合わせると、事実上、個人の詳細な行動追跡ができるのでは、とか。あと、一時 ID の生成って暗号化よりもいい方法がありそう)。
あと、日本版の BlueTrace 実装の開発においてはオープンソース化を強く求めたい。これは、日本のソフトウェア技術者のアイデアを活かすという意味でも、仕様が正しく実装され運用されていることをチェックする意味でも非常に重要だと思う。
続き
追記1 (4/14 14:00)
NHK の報道で言及されていた「民間団体」って、もしかして Code for Japan なのかな?(東京都のコロナ情報サイトを運営しているソフトウェア技術者のボランティア団体)
この記事の通りだとすると、すでに開発はスタートしていて Apple/Google の接触者追跡 API を使う方向で動いているのだろう。上記でも述べたように、オープンソース化に期待したいところ。
政府は民間団体による日本版の開発を待って、近く実用実験に乗り出すことにしています。
追記2 (4/16 10:00)
やはり Code for Japan が開発に関わっているとのこと。上記でも述べているように、適当なタイミングで仕様とソースコードを公開して、プロトコルの詳細やプライバシーを担保する方法についてオープンな議論ができるようにして頂きたい。
追記3 (4/16 16:00)
4月の初め頃に Anti-Covid-19 Tech Team (ACTT) なる枠組みが立ち上がっていたらしい。プロジェクト例として「シンガポールのTrace Togetherアプリケーション日本版の実装検討」にも触れられている。
官庁のIT対応能力を強化すべく、コロナウイルス感染症対策担当大臣をチーム長として、IT政策担当大臣及び規制改革担当大臣が連携し、内閣官房や内閣府、総務省、経済産業省、厚生労働省等、関係省庁からなるテックチームを組成。 テックチームは、民間企業や技術者の協力を得ながら、諸外国の状況も踏まえ、考えられるITやデータの活用を検討し、TECH企業による新たな提案も受けながら、迅速に開発・実装できることを目的とする。
内閣官房に私がチーム長の #新型コロナウイルス感染症対策 テックチーム(Anti-Covid-19 Tech Team #ACTT )を立ち上げ、IT企業など12社のオンライン参加を得て開催。感染拡大防止のためのIT活用を官民協力して迅速にすすめる。早速、今月中旬には米国 #CDC と同様の #チャットボット を導入予定です。 pic.twitter.com/t2HrSOLAV5
— 西村 やすとし (@nishy03) 2020年4月6日
追記4 (4/16 16:00)
Apple/Google が検討してる接触者追跡の技術的詳細について。こちらは、ID のマッチングは中央サーバではなく、感染者の匿名化された ID を広告して各端末内で行うようになっているようだ。こちらの方がプライバシー上の懸念について説明が容易だし、筋が良い気がするな。
今日の #rebuildfm で紹介した、Apple/Google が COVID-19 のコンタクトトレーシングをどう実装するかの技術紹介記事。実際に「誰とどこで」接触したかはそもそも記録されないし、その履歴のマッチングもローカルのオンデバイス上のみで行われる。 https://t.co/FdGBZqovYW
— Tatsuhiko Miyagawa (@miyagawa) 2020年4月12日
Google + Apple が提供する、COVID-19 の Contact Tracing(コンタクトトレーシング)の仕組みを図にまとめました。 pic.twitter.com/rwoGtiDofy
— 太田 祐一 (@yuichiota) 2020年4月13日
Apple のプレスリリースと仕様書はこの辺。
QMK Firmware で Raise/Lower と変換/無変換を同じキーに割り当てる
自作キーボード向けのオープンソースファームウェアの QMK Firmware は、LT(layer, kc) という特殊なキーコードを用意している。これを使うと、通常のキーコード(A とか)とレイヤー切り替えキーを同じキーに同時に割り当てることができるので、例えば、レイヤー切替の LOWER キーと「無変換」を一つのキーに収容するといったことができる。
ところが、この LT キーを押してから離す操作を非常に素早く行うと、レイヤーの切り替えがうまく行われずに誤入力が発生する問題がある。これはキーマップ (keymaps) の設定ではどうにもならないが、代わりに keymap.c の process_record_user 関数に手を加えることで解決できる。
この方法はあぷろさんに教えて頂いたのだが、知見を共有する意味で記事として残しておくことにしたい。具体的な実装例は本文の最後に掲載する。
なぜ親指のキー配置が重要か
僕は Windows や Linux を使う際に、日本語入力の IME オフを「無変換」キーに、IME オンを「変換」キーに割り当てるようにしている。この二つのキーの配置は Mac の JIS キーボードにおける「かな」キーや「英数」キーと同じであり、ホームポジションに置いた親指で操作できるのでアクセスしやすい。また、「半角/全角」キーと違って、現在の入力モードが英語なのか日本語なのかを気にせずに所望のモードへ確実に切り替えることができる。
Windows では歴史的経緯により別の機能が割り当てられてきたが、このようなメリットが考慮されたのか、Windows 10 の次期バージョンではこのキーアサインを既定にすることも検討されている。
僕にとっては、この「確実に切り替えられる」という点が重要で、プログラムを書いたりコマンドを打ち始める前に、とりあえず無変換キーを連打するクセがついてしまっているほどだ。そのようなわけで、自作キーボードにおいても「無変換」と「変換」をなるべく親指でアクセスしやすい位置に置いておきたいという要求がある。
一方で、Planck や Let's Split に代表される 40% キーボードでは Raise と Lower の二つのレイヤー切り替えキーが重要な役割を果たす。この種のキーボードではホームポジションから遠いキーをバッサリと削った結果、数字や記号は Raise/Lower との組み合わせで入力するようになっているので、これらもなるべく親指付近に置いておきたい。
その他にも親指で操作したいキーにはスペースやエンターなどもあるわけで、親指でアクセスしやすい一等地である↓の辺りはいよいよ混み合ってくる。

ところが、親指という指は一般に考えられているほど器用ではないし、可動域もさほどではない。個人的には、親指で使いこなせるキーはせいぜい三つで、理想的には二つに抑えたいという感じがする。だから、使いたいキーが三つあるなら、うち二つのキーを一つの物理キーに収容して使い分けたくなる。
そこで、「変換/無変換」と「Raise/Lower」はそれぞれ単発押し (tap) と長押し (hold) なので、キーの押され方をファームウェアで識別すれば二つのキーを一つの物理キーで扱えるんじゃないか、というアイディアにたどり着く。
LT キーの問題点
QMK Firmware には、LT(layer, kc) という特殊なキーコードが用意されている。これを設定した物理キーを単発押しすると kc で指定したキーコードを送るが、長押しすると代わりに layer に切り替わる。これを使うと単発押しと長押しを一つの物理キーに収められるので、以下のように設定してやれば問題は解決…
#define KC_LOMH LT(_LOWER, KC_MHEN) #define KC_RAHE LT(_RAISE, KC_HENK)
…しない。
これ、動くには動くのだが、おそらく多くの人間が期待していない動作をする。簡単に説明すると、QMK は長押しを「キーが 200 ミリ秒押され続けているか否か」で判定しているのだが、例えば「RAISE 押す → E 押す → RAISE 離す」を非常に素早く入力すると長押しの判定が成立せず、# を入力したいのに E になってしまう上に IME オンも働いてしまい、とても残念なことになる。
これを防ぐには RAISE を押して一呼吸おいてから文字の入力を始める、というような人間側のワークアラウンドが必要で、とてもストレスフルだ。
長押し判定の秒数は TAPPING_TERM という定数で決まっているので、これを小さく設定すれば問題は軽減するが根本的な解決ではない。その上、副作用として、通常の単発押しの受付時間も短くなってしまうので、変換キーを押して 100 ms 以内に離さないと入力が失敗するといったことが起きる。これはこれでつらい。
この件について、一年ほど前に Reddit で相談した際に QMK コントリビュータの人からも話を聞けたのだが、結論としては「あまりいい解決策はない」ということになってしまった。私の理解では、これは QMK の設計の根幹に関わる問題*1なので、残念ながら当分は改善されないと思われる。
解決編
この問題が未解決のまま一年ほど我慢して使っていたのだが、今年に入って ErgoDash mini を作ったのを機に「本格的にどうにかせねばなぁ」という機運が高まってきた。そこで自作キーボード Discord でファームウェアに詳しい人たちに相談したところ、あっさりと解決してしまった。最初から聞いておけば…。
上記の通り、QMK の機能では対応していないので keymaps 配列の設定を工夫しても解決しない。そこで、同じ keymap.c にある process_record_user というキーの上げ下げが通知されるイベントハンドラを自分で実装すれば、Raise/Lower の長押しに関する挙動をカスタマイズできる(よく読み返すと、上記の Reddit スレでも軽く言及されている)。
おそらく、多くのキーボードの keymap.c には以下のようなデフォルト実装が書かれていると思う。
bool process_record_user(uint16_t keycode, keyrecord_t *record) { return true; }
あるいは、最初から以下のようなコードが書かれているかもしれない(update_tri_layer という関数の説明はこの辺にある。ここでは関係ないので無視してよい)。
bool process_record_user(uint16_t keycode, keyrecord_t *record) { switch (keycode) { case LOWER: if (record->event.pressed) { layer_on(_LOWER); update_tri_layer(_LOWER, _RAISE, _ADJUST); } else { layer_off(_LOWER); update_tri_layer(_LOWER, _RAISE, _ADJUST); } return false; break; ... } return true; }
これを書き換えて、LT に頼らずに LOWER キーを押して離した際の挙動をカスタマイズする。例えば:
static bool lower_pressed = false; // (1) bool process_record_user(uint16_t keycode, keyrecord_t *record) { switch (keycode) { case LOWER: if (record->event.pressed) { lower_pressed = true; // (2) layer_on(_LOWER); update_tri_layer(_LOWER, _RAISE, _ADJUST); } else { layer_off(_LOWER); update_tri_layer(_LOWER, _RAISE, _ADJUST); if (lower_pressed) { // (4) register_code(KC_MHEN); // macOS の場合は KC_LANG2 unregister_code(KC_MHEN); } lower_pressed = false; } return false; // (5) break; ... default: // (3) if (record->event.pressed) { // reset the flag lower_pressed = false; } break; } return true; }
ポイントとしては以下のような感じ。
- (1):
LOWERキーの上げ下げを記録するlower_pressed変数(値を保管する箱)を用意する - (2):
LOWERキーが押された(record->event.pressedがtrue)ら、それをlower_pressedに記録する - (3): 他のキーが押されたら
lower_pressedをリセットする(returnはしない) - (4):
LOWERキーを離した時にlower_pressedがリセットされていない時だけ「無変換」キーを入力する- 「
LOWER->E」と組み合わせて押した場合はlower_pressedがリセットされた状態なので無変換キーは入力されない
- 「
- (5):
return false;と書く(LOWERキーについて、以降の QMK 本体側での処理を行わないことを示す)
もう少し複雑な制御(LOWER を長押ししたら、他のキーと組み合わせない場合も「無変換」を入力しない)を実装したバージョンを gist に置いておくので、もしよければご参考までに。
まとめ
このように、QMK は細かいカスタマイズをしようとすると途端に難しくなる場合が多い(これを非プログラマの人にやってもらうのはなかなか厳しい)。この辺りが、「新しい自作キーボードファームウェアを作りたい」という話が出てくる一つの動機になっている。自作キーボード Discord の #arm-keyboard-firmware チャンネルでは、この辺りの話題について議論が交わされているので、興味のある人は覗いてみてほしい。
補足
他の方法について指摘を頂いたので紹介させて頂きたい。特に MACRO_TAP_HOLD_LAYER は有用そうなのでいずれ試してみたい。
自分もタップで変換、ホールドで別キーやりたくて実装してたけど、特にノウハウをまとめてなかった…。このへん→ https://t.co/mJzfRlOgJm https://t.co/oZav24z2GK
— みやおか (@miyaoka) February 2, 2019
自分の場合、update_tri_layer を使わないので、MACRO_TAP_HOLD_LAYERを利用してて、keymap.cを作る際には必須。
— rai_suta (@rai_suta) February 3, 2019
けど認知度が低いのか、使ってるkeymap.cが皆無なんだよね。#qmk_firmware https://t.co/K7qqG63ILb